
The AI arena is buzzing, a battleground where titans like OpenAI, Google, Meta, Mistral, and even IBM are locked in a fierce competition for dominance. Forget the hype – we’ve thrown these contenders into the ring, putting their AI models through a rigorous evaluation. Our recent showdown pitted IBM’s Granite series, OpenAI’s GPT-4.0 and O3 Mini, Perplexity’s Sonar Pro, Google’s Flan models, Meta’s LLaMA, and Mistral’s Mixtral against each other. The results are in, revealing some surprising strengths, glaring weaknesses, and a clear leader emerging from the pack. Let’s break down the action and see who came out on top.
The Gauntlet: Our Evaluation Criteria
To ensure a fair fight, we judged each model across several crucial performance areas:
- Generic Prompt Handling: How well does the model tackle everyday questions and requests?
- Reasoning Prowess: Can the model analyze information, draw logical inferences, and solve complex problems?
- Conversational Fluency: How naturally and engagingly does the model participate in dialogue?
- Retrieval-Augmented Generation (RAG) Mastery: How effectively can the model integrate external knowledge to enhance its responses?
- Multilingual Muscle: How well does the model perform in a diverse set of languages (French, Dutch, German, Italian, Polish, Hungarian, and Swedish)?
- Overall Average Score: A comprehensive measure of effectiveness across all categories.
The Knockout Rounds: How the Models Stack Up
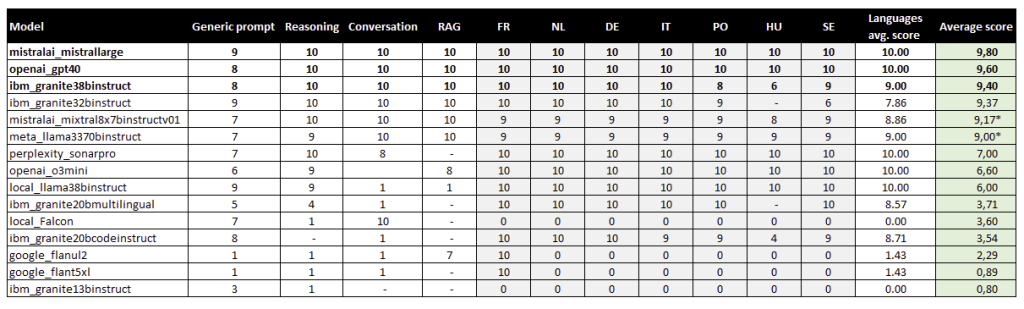
*The language results of those models were correct; however, additional text was included. As a result, a score of 9 was given. This issue may be resolved with effective prompting.
Key Takeaways: The Winners and the Underdogs
Mistral and OpenAI: The Reigning Champions
Mistral Large stands tall as the undisputed champion, boasting an impressive score of 9.8. Its exceptional reasoning, natural conversational abilities, and strong multilingual support make it a force to be reckoned with. Hot on its heels is OpenAI’s GPT-4.0, scoring a commendable 9.6, demonstrating consistent high performance across the board.
IBM’s Granite: Facing an Uphill Battle
The news isn’t great for IBM’s Granite models. The 13B and 20B versions struggled in nearly every category, averaging a low score of 0.8. Their weaknesses in reasoning, multilingual capabilities, and conversational skills make them less competitive for applications demanding deep understanding and language flexibility. While the Granite 32B version shows improvement, landing in the top 3, it still lags behind the leaders, particularly in Polish, Hungarian, and Swedish.
Meta: A Solid Mid-Tier Contender
Meta’s LLaMA 3 70B Instruct offers respectable performance, particularly in reasoning and language support. However, it doesn’t quite reach the elite levels of OpenAI or Mistral.
Mistral’s Mixtral: A Worthy Alternative
Mistral’s Mixtral 8x7binstruct proves to be a strong contender, scoring closely to Meta’s LLaMA 3 70B Instruct, making it an attractive alternative for those seeking robust performance.
Perplexity and Local Models: A Mixed Bag of Hits and Misses
Perplexity’s Sonar Pro shines in reasoning but falters in conversational depth. Local models like LLaMA 3 8B Instruct and Falcon offer moderate performance but aren’t yet ready to challenge the leading proprietary models.
Google’s Flan: Struggling to Compete
Google’s Flan models showed disappointing results across all categories, indicating they have ground to make up in this competitive landscape.
What This Means for Your AI Strategy
For businesses navigating the complex world of AI integration, choosing the right model is paramount. If top-tier performance in reasoning and engaging conversation is your priority, OpenAI GPT-4.0 and Mistral Large are the clear frontrunners. For those prioritizing open-weight models, Meta’s LLaMA 3 70B presents a viable alternative.
As AI technology continues its rapid evolution, evaluations like this are crucial for businesses and researchers to make informed decisions about which models to adopt. The AI arena is dynamic, and the landscape can shift quickly.